
OpenAI won't let you “escape” freely in JSON mode
Accented characters like é may be escaped in JSON as \u00e9. We found that OpenAI's and Azure OpenAI's endpoints can't emit these correctly in JSON mode: after the prefix \u00, the decoder allows only control-character completions (\u0000–\u001f). The output stays valid JSON but holds the wrong bytes — typically a NUL plus literal e9. Once parsed, those control bytes could break some systems and lead to unexpected errors. This is not a JSON limitation but an undocumented endpoint constraint. We describe the failure mode, reproduce it experimentally, and offer practical mitigations.
Authors
- Weixuan Xiao
Published
June 23, 2026
TL;DR
Accented characters like é may be escaped in JSON as \u00e9. We found that OpenAI’s and Azure OpenAI’s endpoints can’t emit these correctly in JSON mode: after the prefix \u00, the decoder allows only control-character completions (\u0000 - \u001f). So é cannot form. The output stays valid JSON but holds the wrong bytes — typically a NUL plus literal e9 (\u0000e9).
Once parsed, those control bytes could break production systems: for exmample, PostgreSQL rejects NUL in text, logs and indexes corrupt silently. This is not a JSON limitation — RFC 8259 does permit any \uXXXX escape. It is an undocumented endpoint constraint from OpenAI and Azure OpenAI.
This applies not only to the accented characters, but also to any UTF-8 characters that the models want to generate in the escaped sequence \uXXXX in JSON, including CJK, Hindi, Cyrillic, etc.
The constraint doesn’t limit what the model can express: JSON can accept raw UTF-8, so é or the other UTF-8 characters don’t necessarily need to be escaped. The trouble starts when prompt examples use \uXXXX escapes (the default in Python!): the model imitates them, attempts the escape, and hits the blocked path. Show raw characters in your examples and the failure never arises.
Introduction
Since the announcement of JSON mode at OpenAI DevDay in 2023, and the broader push toward Structured Outputs (schema-constrained generation) (OpenAI, 2024), many teams have increasingly relied on LLMs to act as trustable serializers: “it can just return valid JSON as requested and we can use the JSON directly in production.”
In practice, these features do a great job at enforcing outer structure—objects vs arrays, required keys, field types, enums, and “no extra fields.” But they do not automatically guarantee the semantic correctness of the content.
This article describes a failure mode we observed under OpenAI’s JSON mode, where the output can be syntactically valid JSON yet contain corrupted strings, with downstream consequences — such as database errors (especially for modern solutions using PostgreSQL as backend, such as Neon and Supabase), confusing system logs due to invisible and unexpected characters, frontend failure due to serialization, etc.
We first present what we observed in production and explain Structured Outputs and the JSON grammar. Then, we demonstrate our experiments and the results to reproduce the failures under JSON mode on OpenAI endpoints. Finally, we show our findings and conclude with mitigations and takeaways.
Observations
At Giskard, we have some Python tooling that uses a PostgreSQL database and OpenAI endpoints. The application:
- sends requests to OpenAI endpoints and enables JSON mode
- parses the JSON results
- saves the parsed contents in the database.
In backend logs, we occasionally saw errors where PostgreSQL rejected an insert of a string field because it contained a null byte (\x00, which PostgreSQL does not accept in text fields):
invalid byte sequence for encoding "UTF8": 0x00We found that these invalid strings were coming from LLM outputs and had mismatches in accented characters:
- What we expected: French characters with accents in the words, e.g.
é - What we actually got: some fragments like
Cr\x00e9ditin Python backend
A simplified illustration in the Python string:
expected: "é" ( U+00E9 as unicode codepoint)
got: "\\x00e9" ( a NUL byte followed by 2 ASCII letters "e9" )Intuitively, it looks like the model meant to produce \u00e9 but “with extra zeros”, yielding \u0000e9. After the JSON parsing in Python, the \u0000 becomes a \x00 (NUL byte) and the e9 literally becomes 2 letters — e and 9 in Python string. The PostgreSQL database actually validates the UTF-8 string to be saved, which led to the failure due to the existing NUL.
On the Internet, we also find related reports — the similar issue also occurs for German letters, and is unresolved on the OpenAI community forum.
The JSON mode, that we enabled, is part of the implementation of Structured Outputs. It could guarantee that the generated contents follow the required JSON structure.
In JSON specification, RFC 8259 §7 (Strings) specifies that JSON strings can include Unicode characters (UTF‑8), or escape sequences as follows:
- A Unicode escape sequence has the form:
\u+ exactly four hex digits, representing one UTF‑16 code unit. - ASCII control characters
U+0000–U+001Fcannot appear raw inside JSON strings, but they are allowed when escaped (e.g.,\u0000,\u001a,\u001f). - Characters above
U+FFFFcan be represented as a surrogate pair (e.g.,\uD83D\uDE00for 😀).
Therefore, both é and \u00e9 could be used to represent é (U+00E9) in a JSON string.
Notice that the LLM output presented in the example above is also a valid JSON string: "\u0000e9". However, it does not represent é. Instead, it represents:
\u0000(NUL)- followed by the literal characters
eand9
JSON has no semantic notion of “you typed too many zeros.” The parser will accept it as a normal string, and the downstream system will receive a string that actually contains a null byte control character in this case.
Validations
To reproduce and understand the issue, we prompted the LLM to directly generate JSON strings containing non-ASCII characters.
The template is:
<system>
You are a JSON generator.
Respond with a single JSON object that includes only:
- "encoded": a single-entry object whose key is the exact surface word (Unicode) and whose value is a JSON string for the same word using \\uXXXX escapes for non-ASCII codepoints.
Do not add any other top-level keys.
Here is an example for the text "©opyright":
{
"encoded": {
"©opyright": "\\u00a9opyright"
}
}
</system>
<user>
Give me the escaped unicode JSON representation for "<LETTER>":
</user>where <LETTER> is a non-ASCII letter in French or other European languages (e.g. à, œ).
We first ran experimentations on Azure gpt-4o endpoint, without enforcing JSON grammar (JSON mode is not enabled) for 2380 tests (10 repetitions for 17 non-ASCII letters with uppercase and lowercase, and varied temperatures). In around 99.8% tests, it generated the escaped forms of the letters without any issues. The 5 wrong generations are caused by the higher temperatures — one error under 1.7 and four for 2.0. Then, we turned on JSON mode. All the tests are failing with wrong generations or corrupted contents:
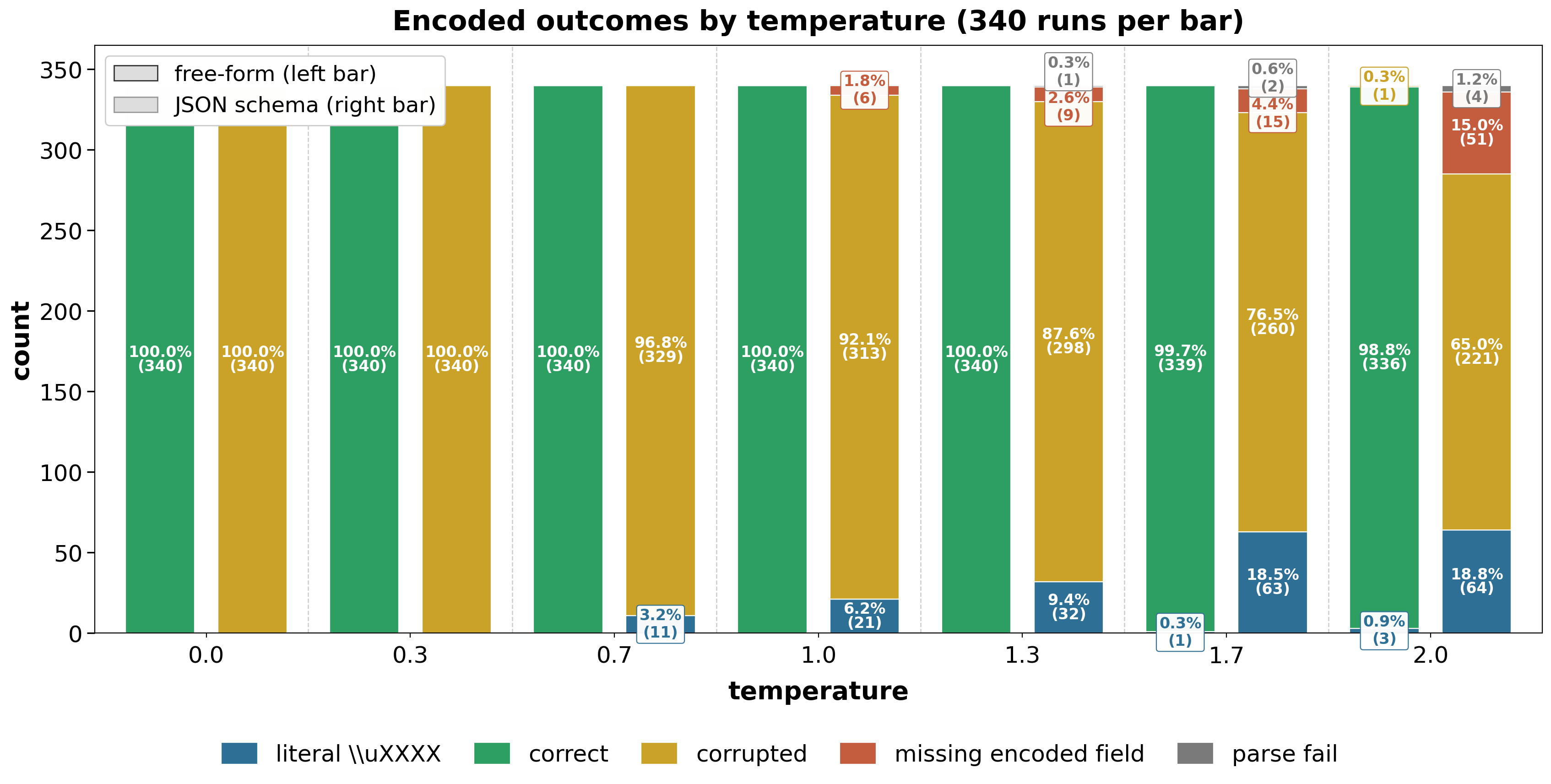
Here are some representative causes of the corruptions:
- leading redundant 0:
- À is U+00C0
{"encoded": {"À": "\\u0000c0"}}
- Æ is U+00C6
{"encoded": {"Æ": "\\u0006c"}}
- À is U+00C0
- wrong values:
- Æ is U+00C6
{"encoded": {"Æ": "\\u001e"}}
- Ä is U+00C4
{"encoded": {"Ä": "\\u001c"}}
- Ü is U+00DC
{"encoded": {"Ü": "\\u001c"}}
- Ÿ is U+0178
{"encoded": {"Ÿ": "\\u00178"}}
- Æ is U+00C6
- or both of the above:
- Æ is U+00C6
{"encoded": {"Æ": "\\u00066"}}
- Ä is U+00C4
{"encoded": {"Ä": "\\u000041"}}{"encoded": {"Ä": "\\u000046"}}
- Æ is U+00C6
Some discussions and debates warn that format constraints can probably hurt model performance (Tam & others, 2024), though others argue constraints are necessary in production when implemented correctly (Kurt, 2024). Recent work on the format tax (Lee et al., 2026) and on separating deliberation from the payload (Banerjee et al., 2025; Nguyen et al., 2026) motivates adding a reasoning field so the model can think before outputting the encoded value, e.g.:
"© is U+00A9. In JSON I represent it as \\\\u00a9 before the rest of the letters."The results remain similar — all 2380 generations failed with the corrupted contents. The reasoning field often states the correct escape, yet encoded still diverges. We can see that the LLM does know what to output, but it cannot output correctly with \\u (the single backslash u, which is parsed as an escaped character):
{
"reasoning": "Ô is U+00D4. In JSON I represent it as \\\\u00d4.",
"encoded": {"Ô": "\\u0000d4"}
}Here are detailed results of the failures:
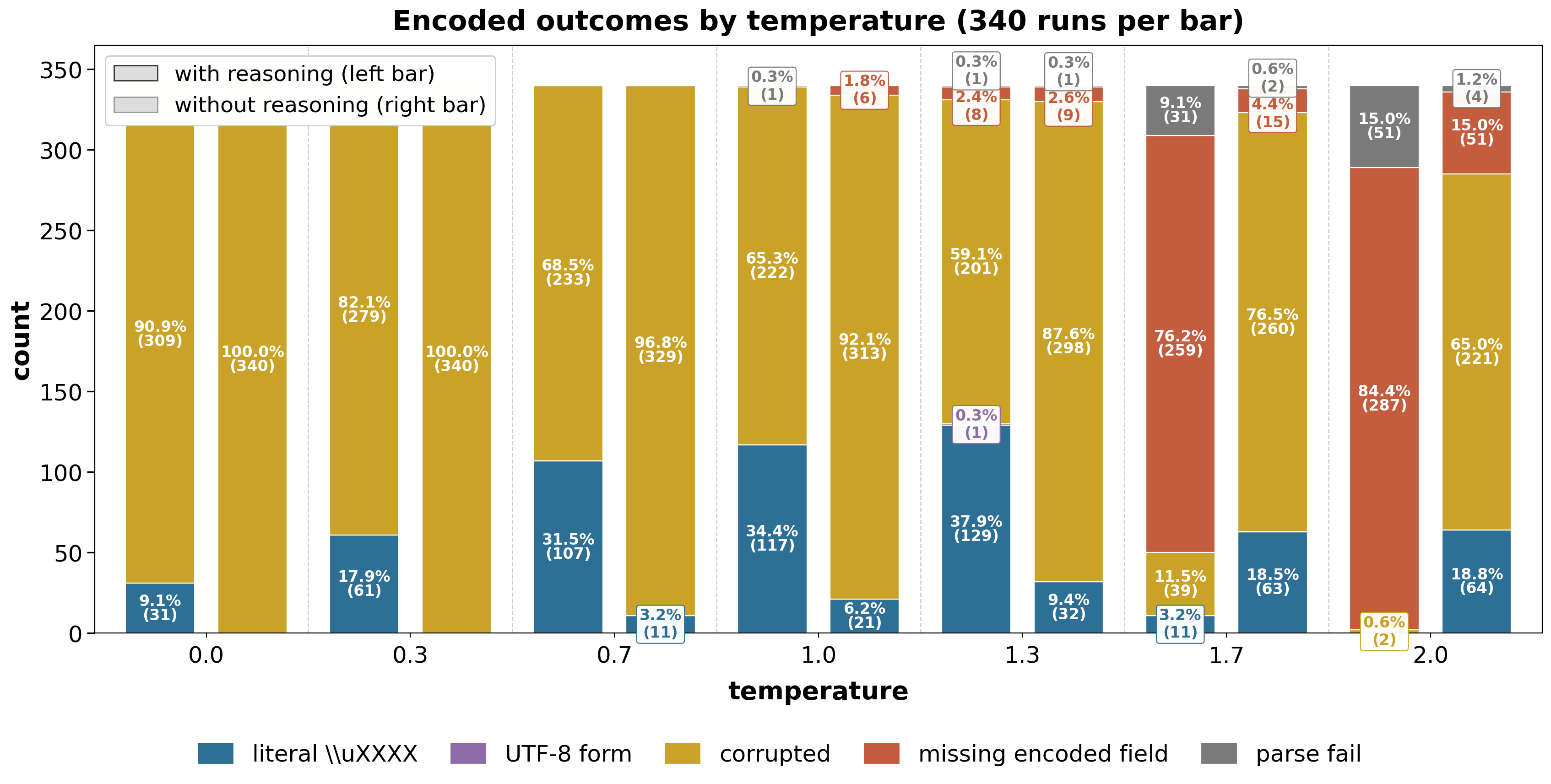
With the results above, we can observe that, once the JSON mode is turned on with Azure OpenAI endpoints (or OpenAI official endpoints), the model is only capable of outputting:
- either the double-backslash
\\\\uin JSON string, which can not be decoded to the original letter, but to a string with 6 literal characters —"\u00e0" - or the single-backslash with the corrupted hex value.
We also did a supplementary run with a subset of the same task on our self-hosted vLLM OpenAI’s gpt-oss-20b model (which shares the same base tokenizer as Azure OpenAI’s gpt-4o, despite that gpt-4o contains some appended new tokens in the vocabulary, but they will not affect the cases of single letters). There were no such corruption issues at all. This may suggest that the issue is not caused by the models or the tokenizers themselves, but by the JSON mode on the endpoints side.
Hypothesis: OpenAI’s JSON mode constrains \u00 escaped sequence to control-character only
Based on the results of the experiments, we believe the failures are not from the LLM predicting the wrong tokens, but from the systems implementing the JSON grammar constraints in Azure OpenAI and OpenAI’s official endpoints.
In endpoints from both providers, we observed that in Structured Outputs JSON mode, once the model has generated the prefix \u00, the top-10 candidates for the next token only contain control-character range. This could indicate that the endpoint’s constrained decoder only permits completions in this range. There is a stricter grammar in JSON mode: only control characters, including \u00[0,1][0-9a-f] (i.e., \u0000 … \u001f) and \u007f (DEL) are permitted.
This restriction is not imposed by JSON (RFC 8259 allows any \uXXXX escape) or claimed in OpenAI’s documentation (OpenAI, 2024); it appears to be specific to these endpoints’ JSON-mode decoding.
The corruptions are happening 100%; we managed to reproduce this consistently across the whole OpenAI model family (from gpt-4o up to gpt-5.2) on Azure AI, and gpt-3.5-turbo and gpt-4o on OpenAI. Such corruptions do not happen to both OpenAI’s gpt-oss-20b model and third-party qwen3.5-4B model, hosted by vLLM.
But our hypothesis still needs to be confirmed by OpenAI, since we do not have enough information about their systems.
Why this breaks escapes like \u00e9
Let’s take the French letter é again, which is normally written as \u00e9.
Under the observed restriction:
- The model can generate the prefix
\u00. - At the next step, tokens corresponding to
e/e9are masked and excluded; the decoder only allows00,01, …1f. - After leaving that constrained region, we’ve observed three common outcomes:
- The model insists on the intended value → it emits
\u0000(NUL) and then literaleand9, producing three characters: NUL +e+9. - The model drifts into corruption → it emits
\u000e+ literal9(two characters), or another control escape like\u0001+ literal9. - The model believes it succeeded → the decoded text contains control characters (e.g.,
\u0002), matching patterns liker\x02f\x02rence.
- The model insists on the intended value → it emits
- After JSON parsing in Python, these control characters materialize as
\x0Xor\x1Xbytes, which can trigger downstream failures that we mentioned earlier.
Mitigations — practical guidance
Recommended approach, if you are using the LLM endpoints from OpenAI or Azure OpenAI:
- Do not demonstrate or strongly encourage
\uXXXX-style escapes in prompts; models often mimic the formatting style you show. - Do not proactively ask for ASCII-only output; notice that in Python, the default parameter
ensure_asciiofjson.dumpsisTrue, which generates\uXXXXfor non-ASCII characters. This might encourage the models to use escaped sequences in its output. Explicitly settingensure_ascii=Falseis highly recommended. - Add checks for anomalies in the output, on top of schema validation:
- Reject or sanitize control characters (especially
U+0000and generallyU+0000–U+001FplusU+007F)
- Reject or sanitize control characters (especially
Takeaways
Following the trend of open-weight models and LLM agents, LLM API providers are emerging. They might have different implementations and considerations in the different components — without documenting every detail. Some behaviors are by-design and expected. For example, OpenAI’s or Azure OpenAI’s endpoints won’t let you “escape” freely in JSON mode — the constraint only allows control characters to be escaped:
- This could be by-design and on-purpose from OpenAI, because UTF-8 string in JSON can already represent anything except control characters.
- But this behavior appears undocumented in OpenAI’s documentation (OpenAI, 2024), which has been causing confusion for developers for years.
Also, for JSON, XML, SQL literals, shell escaping, HTML entities, URL encoding, and similar tasks:
- LLMs can express their own intents,
- but escaping and serialization are handled by the libraries besides the LLMs.
The main points are simple in practice:
- log system behaviors and proactively find out the subtle failures;
- keep evaluating and testing your LLMs and agents, before it causes real harms in production. If you need help in securing your agents, reach out to the Giskard team.