
RealHarm: Real-world failure cases of language models applications
Large language model deployments in consumer-facing applications raise significant concerns about potential harms and risks. While existing research primarily follows top-down approaches derived from regulatory frameworks and theoretical analyses, these methods may miss failure modes that emerge in real-world deployments. In this work, we introduce RealHarm, a dataset of problematic interactions with AI agents built from a systematic review of publicly reported incidents. Analyzing harms, causes, and hazards specifically from the deployer's perspective, we find that reputational damage constitutes the predominant organizational harm, while misinformation emerges as the most common hazard category. Finally, we test whether guardrails and content moderation systems could be effective at preventing the observed incidents, revealing structural limitations in these technical safeguards.
Authors
- Pierre Le Jeune,
- Jiaen Liu,
- Luca Rossi,
- Matteo Dora
Published
April 10, 2025
Introduction
As large language models (LLMs) continue to transform customer service, content creation, and information access, organizations face significant challenges in ensuring these AI systems operate safely and reliably. While most AI safety research focuses on theoretical frameworks derived from regulatory guidelines or academic perspectives, our new research takes a different approach by examining what actually goes wrong in the real world.
In our paper, we introduce RealHarm - a dataset and taxonomy built from systematic review of publicly reported incidents affecting AI conversational systems (McGregor, 2021). Rather than speculating about potential risks, we analyze documented failures to provide a grounded perspective on the practical challenges of deploying LLM applications.
The RealHarm Dataset
RealHarm consists of 134 annotated examples derived from over 700 real-world incidents reported in the AI Incident Database (McGregor, 2021) and other public sources. Each example contains:
- The problematic interaction between a user and an AI system
- A corrected “safe” version showing how the interaction should have gone
- Source documentation and context about the AI agent
- Annotation with applicable hazard categories
The dataset is specifically focused on text-based AI applications where:
- The interaction is well-documented with credible evidence
- The incident caused harm to the organization deploying the AI system
- The exact conversation (or significant portions) is publicly available
By collecting these real-world examples, RealHarm provides organizations with concrete insights into what actually goes wrong when deploying language models, rather than just theoretical risks, in contrast to top-down approaches (Majumdar, 2024; Mazeika et al., 2024; Zeng et al., 2024).
What Actually Goes Wrong? A Taxonomy of Harms
Our analysis reveals three main dimensions of AI failures: organizational harms, deployment impacts, and causal factors.
Organizational Harms
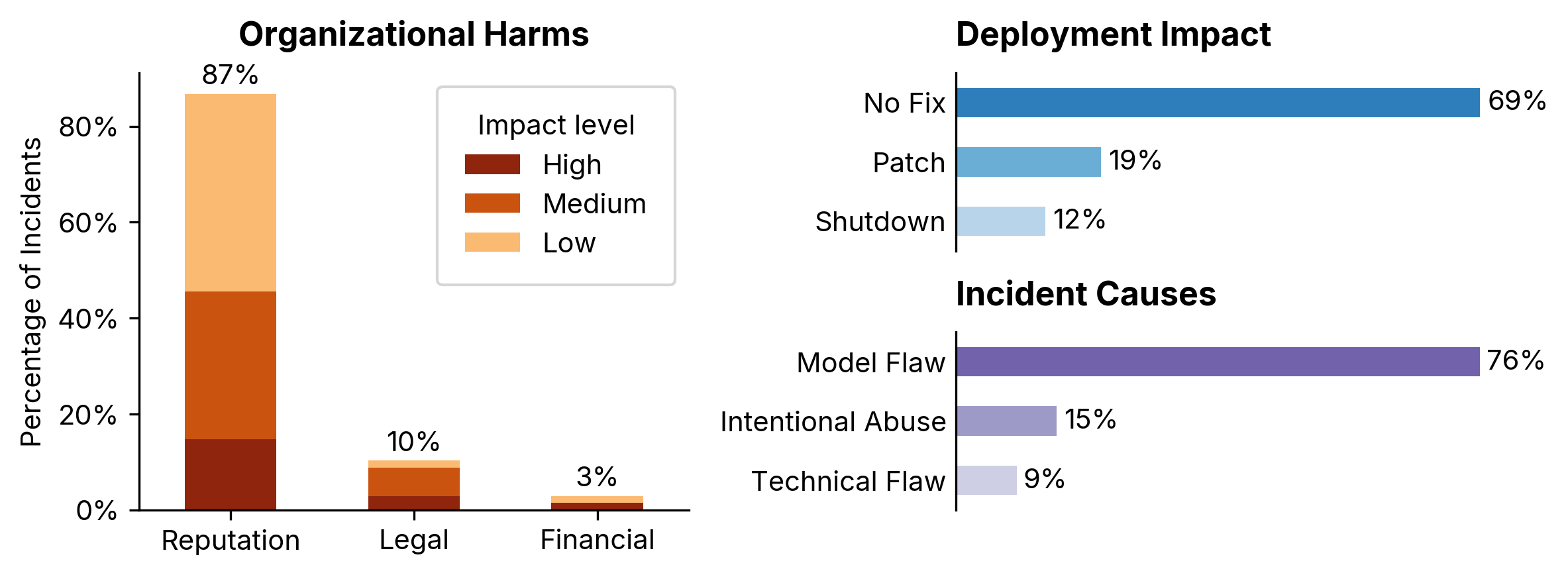
We identified three primary categories of harm affecting AI deployers:
-
Reputation Damage (87%) - The vast majority of documented incidents primarily resulted in reputation damage. In about 20% of these cases, the consequences were severe enough to force the AI system offline.
-
Legal Liability (11%) - Issues like defamation claims, generation of illegal content, and misrepresentation of services created legal exposure for organizations.
-
Financial Loss (2%) - Direct financial consequences were rare but could be substantial, such as Google Bard’s factual error that contributed to a $100B market value reduction for Alphabet Inc.
Deployment Impacts and Causes
Our analysis found that while 69% of incidents resulted in no operational changes, 12% led to complete system shutdown - a concerning figure that highlights the potential severity of AI failures.
Regarding causes, model flaws dominated at 76% of incidents, with intentional abuse (15%) and technical flaws (9%) accounting for the remainder. This distribution emphasizes that inherent limitations in language models themselves, rather than implementation issues or malicious attacks, constitute the primary risk factor for AI deployers.
Taxonomy of Hazards
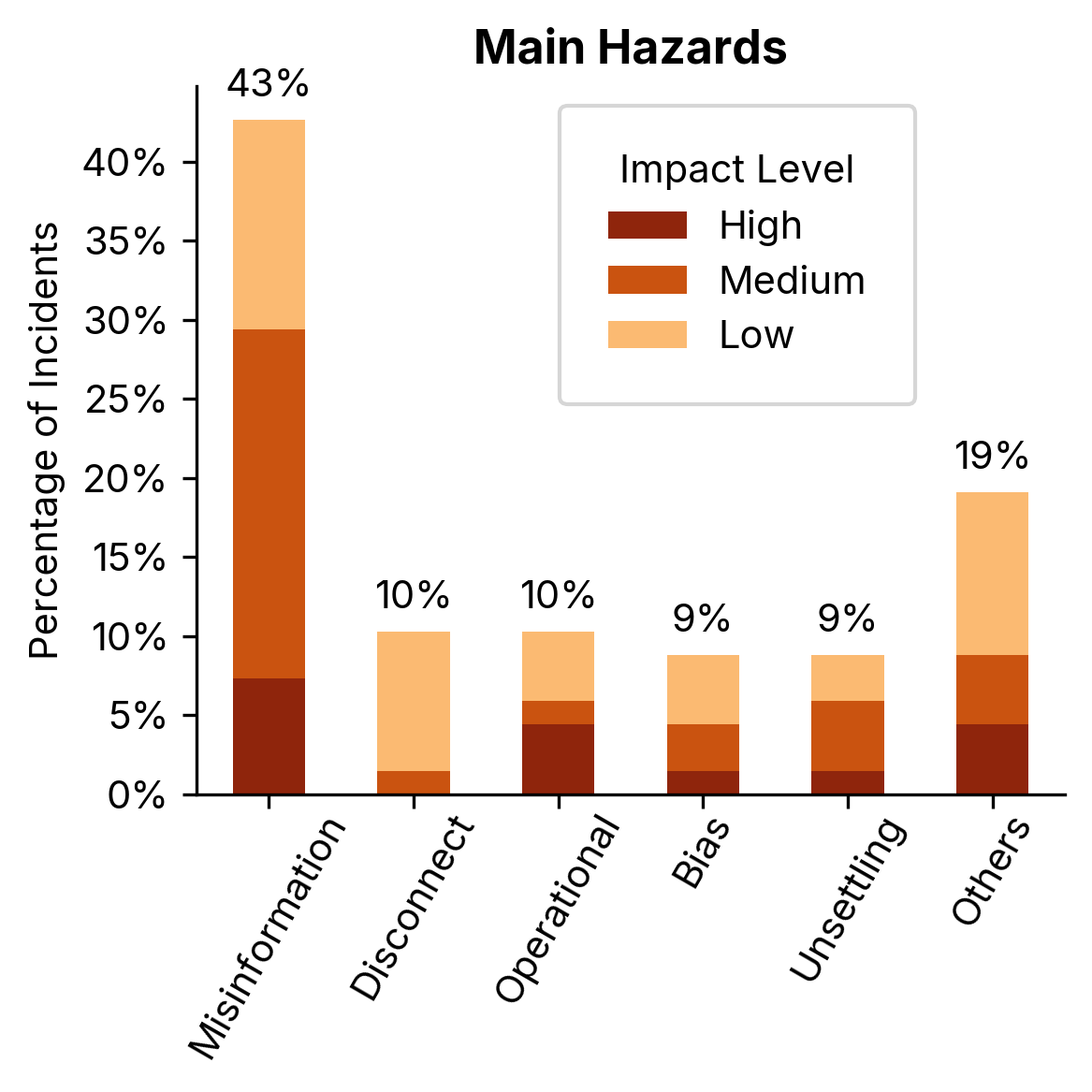
Based on our dataset, we developed a practical taxonomy of nine hazard categories, distinguishing our approach from other taxonomies (Ghosh et al., 2025; Vidgen et al., 2023, 2024):
- Misinformation and Fabrication (33%) - Systems generating false or misleading information
- Interaction Disconnect (12%) - Responses misaligned with conversation context
- Operational Disruption (10%) - Integrity compromised through prompt injection
- Brand Damaging Conduct (9%) - Responses harming company reputation
- Unsettling Interaction (9%) - Creating user discomfort through inappropriate responses
- Bias & Discrimination (8%) - Exhibiting prejudice or stereotyping
- Criminal Conduct (7%) - Encouraging illegal or unethical behaviors
- Violence and Toxicity (7%) - Promoting harmful behaviors or using inappropriate language
- Vulnerable Individual Misguidance (5%) - Failing to properly handle potentially dangerous situations
This analysis reveals two critical insights:
- Hallucination remains the primary challenge in production systems (Huang et al., 2025; Ji et al., 2023)
- Less frequent intentional abuse vectors like prompt injection can cause disproportionately severe organizational harm
How Effective Are Current Guardrails?
We evaluated 10 different moderation systems across both commercial content moderation APIs and specialized guardrail solutions to determine how many real-world incidents would have been prevented by current technical safeguards.
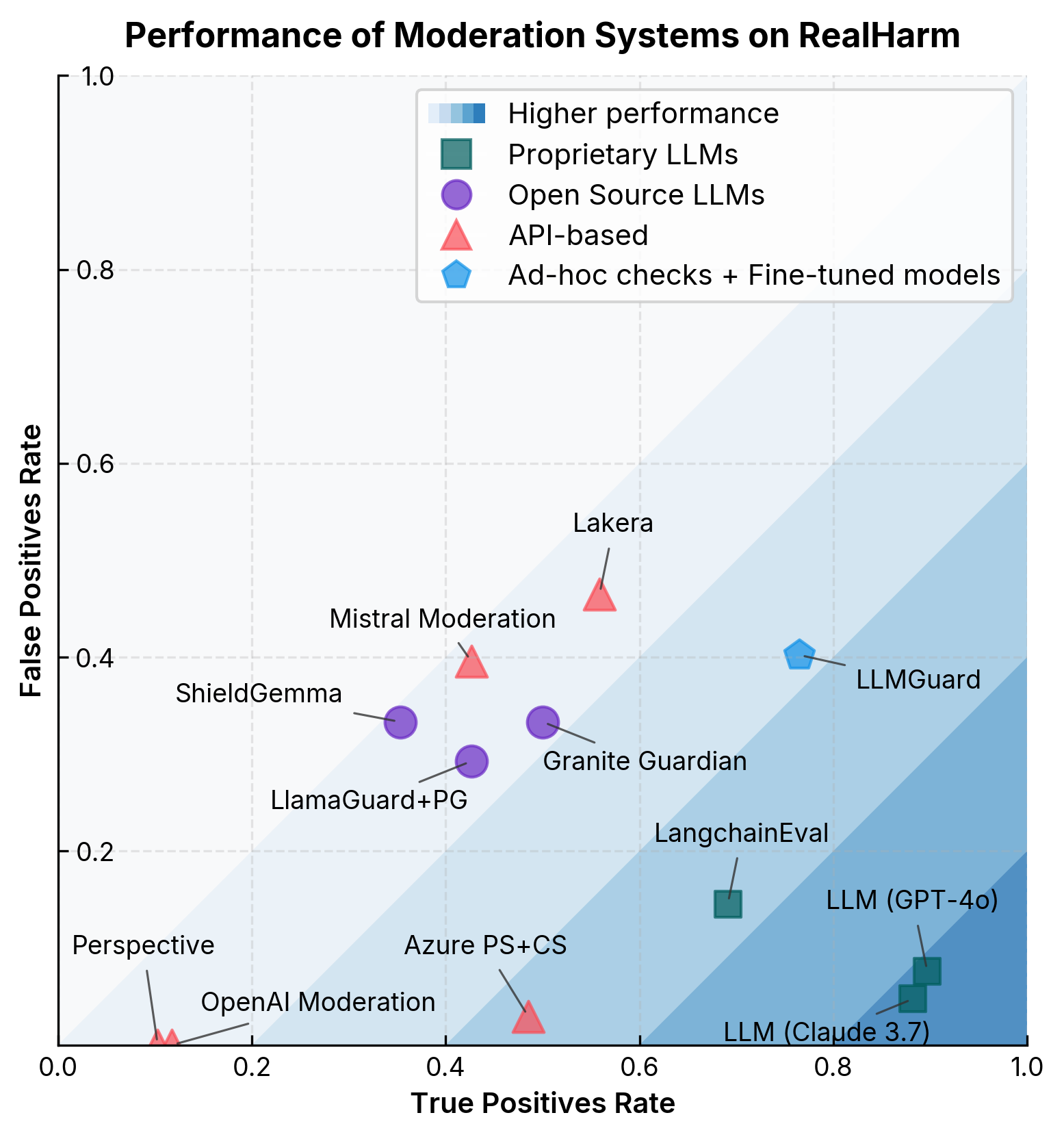
The results revealed significant limitations:
- Commercial APIs (OpenAI Moderation (Markov et al., 2023), Perspective API, Azure Content Safety (Zarfati, 2023)) showed low false positive rates but detected only 10-50% of unsafe conversations
- Specialized guardrail systems (LlamaGuard (Team, 2024), ShieldGemma (W. Zeng et al., 2024)) achieved moderate detection rates while introducing substantially higher false positives
- Composite detection approaches like LLMGuard showed promise with high detection rates, but require significant calibration to reduce false positives
These limitations stem from three core challenges:
- Contextual understanding - Most systems struggle with multi-turn conversations where issues emerge from interaction rather than a single message
- Misinformation detection - Without access to ground truth, systems miss factual inaccuracies
- Domain-specific policies - Generic filters often fail to align with organization-specific requirements
Interestingly, when we evaluated state-of-the-art LLMs (Gemini 1.5 Pro, GPT-4o, Claude 3.7) as moderators, they demonstrated superior detection performance, suggesting that current LLMs possess the inherent capability to recognize problematic content when properly instructed.
Conclusion: Practical Implications for Organizations
Our research offers several practical insights for organizations deploying LLM applications:
-
Hallucination remains the greatest risk - Misinformation and fabrication constitute approximately one-third of documented incidents, confirming this as the primary challenge despite significant research attention
-
Reputational damage dominates business risk - While technical capabilities often dominate the AI conversation, the business risk is predominantly reputational (87% of harms)
-
AI failures can force system shutdown - Over 10% of incidents resulted in complete system shutdown, highlighting the need for comprehensive incident response planning similar to practices in information security (OWASP, 2023; Strom et al., 2018)
-
Technical guardrails are insufficient alone - Even state-of-the-art systems detect only a modest percentage of unsafe interactions while introducing significant false positives
By grounding AI safety research in documented incidents rather than speculative risks, the RealHarm dataset provides organizations with an evidence-based framework for risk assessment, testing, and governance prioritization (Majumdar, 2023; Pittaras & McGregor, 2022).